Atlas Search Overview
MongoDB's Atlas Search allows fine-grained text indexing and querying of data
on your Atlas cluster. It enables advanced search functionality for
your applications without any additional management or separate search
system alongside your database. Atlas Search provides options for several
kinds of text analyzers, a rich query
language that uses Atlas Search aggregation pipeline
stages like $search and $searchMeta in
conjunction with other MongoDB aggregation pipeline stages, and
score-based results ranking.
Atlas Search is available on Atlas instances running MongoDB 4.2 or higher versions only.
Atlas Search Architecture
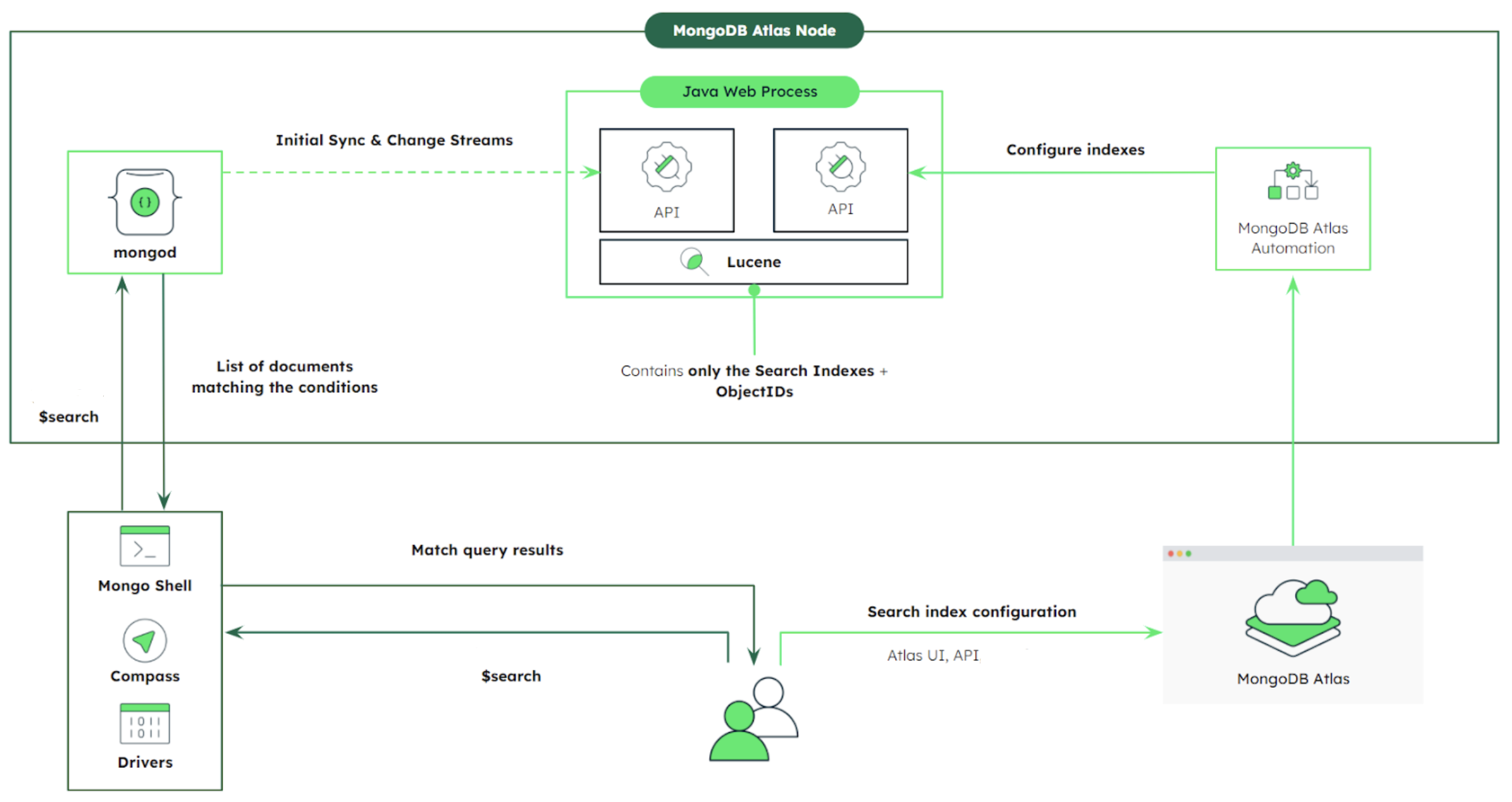
The Atlas Search mongot Java web process uses Apache Lucene and runs alongside mongod on each
node in the Atlas cluster. The mongot process:
- Creates Atlas Search indexes based on the rules in the index definition for the collection.
- Monitors change streams for the current state of the documents and index changes for the collections for which you defined Atlas Search indexes.
- Processes Atlas Search queries and returns matching documents.
Atlas Search Indexes
When you configure one or more Atlas Search search indexes, Atlas enables
the mongot process on the nodes in the cluster. Each mongot
process talks to the mongod on the same node. To create and update
indexes, the mongot process performs collection scans on the
backend database and opens change streams for each index.
You can specify the fields to index using the following:
- Dynamic mappings, which enables Atlas Search to automatically index all the fields of supported types in each document. This takes disk space and might negatively impact cluster performance.
- Static mappings, which allows you to selectively identify the fields to index.
Atlas Search performs inverted indexing and stores the indexed fields on disk. The data stored on Atlas Search isn't an identical copy of data from the collection on your Atlas cluster, but it still takes some disk space and memory.
Atlas Search provides built-in analyzers for creating indexable terms that correct for differences in punctuation, capitalization, stop words, and more. Analyzers apply parsing and language rules to the query. You can also create a custom analyzer using available built in character filters, tokenizers, and token filters. To learn more about the built-in and custom analyzers, see Process Data with Analyzers.
For text fields, the mongot performs the following to create
indexable tokens:
- Analysis of the text
- Tokenization, which is breaking up of words in a string to indexable tokens
- Normalization, such as transforming the text to lower case, folding diacritics, and removing stop words
- Stemming, such as ignoring plural and other word forms to index the word in the most reduced form
To learn more about Atlas Search support for other data types, see
BSON Data Types and Atlas Search Field Types. The mongot
process stores the indexed fields and the _id field on disk per
index for the collections on the cluster.
If you modify an existing index, Atlas Search performs a no-downtime rebuild of the index. This allows you to continue using the old index for existing and new queries until the index rebuild is complete.
If you make changes to the collection for which you defined Atlas Search
indexes, the latest data might not be available immediately for
queries. However, mongot monitors the change streams, which allows
it to update stored copies of data, and Atlas Search indexes are eventually
consistent.
After you set up an Atlas Search index for a collection, you can run queries against the indexed fields.
Atlas Search Queries
Atlas Search queries take the form of an aggregation pipeline stage. Atlas Search provides $search, which must be the
first stage in the query pipeline, and $searchMeta stages.
These stages can be used in conjunction with other aggregation
pipeline stages in your query pipeline. To learn more
about these pipeline stages, see Choose an Aggregation Pipeline Stage.
Atlas Search also provides query operators and collectors that you can use inside the Choose an Aggregation Pipeline Stage. The Atlas Search operators provide ways to locate and retrieve matching data from the collection on your Atlas cluster. The collector returns a document representing the search metadata results.
You can use Atlas Search operators to query terms, phrases, geographic shapes
and points, numeric values, synonymous terms, and more. You can also
search using regex and wildcard expressions. The Atlas Search
compound operator allows you to combine multiple operators
inside your $search stage to perform a complex search and
filter of data based on what must, must not, or should be present
in the documents returned by Atlas Search. You can use the compound
operator to also match or filter documents in the $search
stage itself. Running $match after $search is
less performant than running $search with the
compound operator.
To learn more about the syntax, options, and usage of the various Atlas Search operators, see Use Operators and Collectors in Queries.
When you run a query, the query first goes to the MongoDB process,
which is mongod for a replica set cluster or mongos for a
sharded cluster. For sharded clusters, your cluster data is partitioned
across mongod instances and each mongot knows about the data on
the mongod on the same node only. Therefore, you can't run queries
that target a particular shard. mongos directs the queries to all
shards, making these scatter gather queries.
The MongoDB process routes the query to the mongot on the same
node. Atlas Search performs the search and scoring and returns the document
IDs and other search metadata for the matching results to mongod.
The mongod then performs a full document lookup implicitly for the
matching results and then returns the results to the client.
Atlas Search associates a relevance-based score with every document in the result set. The relevance-based scoring allows the documents to be returned in order from highest score to lowest. Atlas Search scores documents higher if the query term appears frequently in a document and lower if the query term appears across many documents in the collection. Atlas Search also supports customizing the relevance-based default score by boosting, decaying, etc. To learn more about the various ways in which you can customize the resulting scores, see Customize the Score in Results.
Next Steps
For hands-on experience creating Atlas Search indexes and running Atlas Search queries against the sample datasets, try the tutorials in the following pages: